Hi,
I’ve built up connection from S3 to redshift.
My Amazon S3 bucket has a csv file that i am trying to replicate but when it fetches the schema from the source it names it as dataset name given in source configuration instead of the actual file name.
is this the expected behavior? Because my understanding for the field “Dataset” is that it is the name of the table at the destination but here it is also naming the source stream with the same name
My file in AMAZON S3 BUCKET
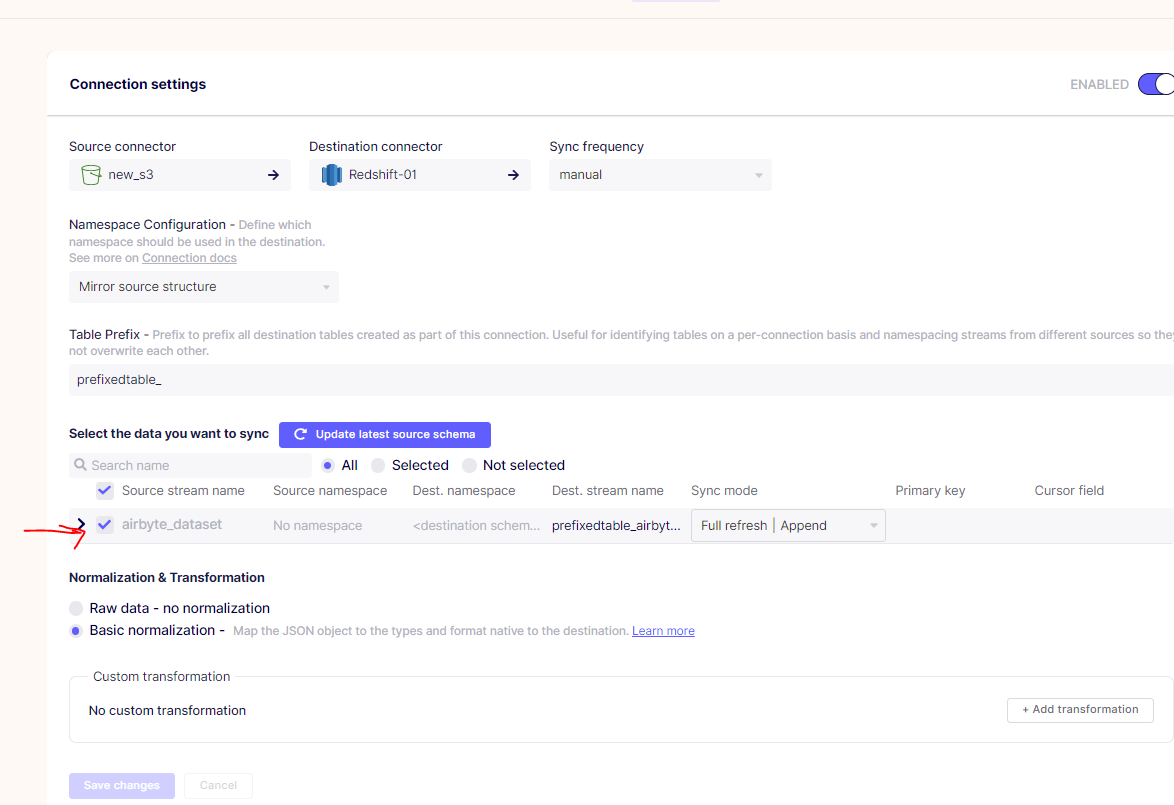
Source configs settings > Here you can observe that dataset is named as “airbyte_dataset”
Now fetched stream is named same instead of the actual file name that i have in my bucket
Hi @MahakUrooj,
The S3 connector is made to sync multiple files with the same schema, and gather these files into the logic of streams.
Now fetched stream is named same instead of the actual file name that i have in my bucket
You have set the dataset name manually and this connector can only handle a single stream, so this behavior is the expected one.
Let me know if you have additional questions. Is something blocking you with the current connector behavior?
Hi there from the Community Assistance team.
We’re letting you know about an issue we discovered with the back-end process we use to handle topics and responses on the forum. If you experienced a situation where you posted the last message in a topic that did not receive any further replies, please open a new topic to continue the discussion. In addition, if you’re having a problem and find a closed topic on the subject, go ahead and open a new topic on it and we’ll follow up with you. We apologize for the inconvenience, and appreciate your willingness to work with us to provide a supportive community.