- Is this your first time deploying Airbyte?: Yes
- OS Version / Instance: MacOS
- Memory / Disk: 16Gb / 1 Tb
- Deployment: Docker
- Airbyte Version: 0.40.10
- Source name/version: adhamsuliman/source-call-rail
- Destination name/version: dev
- Step: The issue is happening during sync
Description:
Hello, I’m in the process of implementing my first custom source for Call Rails. I’ll first discuss what I’ve accomplished and then provide details as to where I’m stuck.
Accomplished thus far:
- created a
Python HTTP API Source - created secrets/config.json
- created source.py
class CallRailStream(HttpStream, ABC):
url_base = "https://api.callrail.com/v3/a/"
def __init__(self, authenticator, config: Mapping[str, Any], **kwargs):
super().__init__(authenticator=authenticator, **kwargs)
self.access_key = config["access_key"]
self.account_id = config["account_id"]
def next_page_token(self, response: requests.Response) -> Optional[Mapping[str, Any]]:
"""
TODO: Override this method to define a pagination strategy. If you will not be using pagination, no action is required - just return None.
This method should return a Mapping (e.g: dict) containing whatever information required to make paginated requests. This dict is passed
to most other methods in this class to help you form headers, request bodies, query params, etc..
For example, if the API accepts a 'page' parameter to determine which page of the result to return, and a response from the API contains a
'page' number, then this method should probably return a dict {'page': response.json()['page'] + 1} to increment the page count by 1.
The request_params method should then read the input next_page_token and set the 'page' param to next_page_token['page'].
:param response: the most recent response from the API
:return If there is another page in the result, a mapping (e.g: dict) containing information needed to query the next page in the response.
If there are no more pages in the result, return None.
"""
return None
def request_params(
self, stream_state: Mapping[str, Any], stream_slice: Mapping[str, any] = None, next_page_token: Mapping[str, Any] = None
) -> MutableMapping[str, Any]:
"""
TODO: Override this method to define any query parameters to be set. Remove this method if you don't need to define request params.
Usually contains common params e.g. pagination size etc.
"""
return stream_slice
class Calls(CallRailStream):
"""
TODO: Change class name to match the table/data source this stream corresponds to.
"""
# TODO: Fill in the primary key. Required. This is usually a unique field in the stream, like an ID or a timestamp.
primary_key = "id"
def path(
self, stream_state: Mapping[str, Any] = None, stream_slice: Mapping[str, Any] = None, next_page_token: Mapping[str, Any] = None
) -> str:
"""
TODO: Override this method to define the path this stream corresponds to. E.g. if the url is https://example-api.com/v1/customers then this
should return "customers". Required.
"""
return f"{self.account_id}/calls.json?"
def parse_response(self, response: requests.Response, **kwargs) -> Iterable[Mapping]:
"""
TODO: Override this method to define how a response is parsed.
:return an iterable containing each record in the response
"""
for d in response.json()['calls']:
yield d #["calls"]
# Source
class SourceCallRail(AbstractSource):
def check_connection(self, logger, config) -> Tuple[bool, any]:
"""
TODO: Implement a connection check to validate that the user-provided config can be used to connect to the underlying API
See https://github.com/airbytehq/airbyte/blob/master/airbyte-integrations/connectors/source-stripe/source_stripe/source.py#L232
for an example.
:param config: the user-input config object conforming to the connector's spec.yaml
:param logger: logger object
:return Tuple[bool, any]: (True, None) if the input config can be used to connect to the API successfully, (False, error) otherwise.
"""
return True, None
def streams(self, config: Mapping[str, Any]) -> List[Stream]:
"""
TODO: Replace the streams below with your own streams.
:param config: A Mapping of the user input configuration as defined in the connector spec.
"""
auth = TokenAuthenticator(token=config["access_key"]) # Oauth2Authenticator is also available if you need oauth support
headers = {"Authorization": f"Token token={config['access_key']}"}
response = requests.get("https://api.callrail.com/v3/a.json", headers=headers)
response.raise_for_status()
# Calls(authenticator=auth, config=config),
return [Calls(authenticator=auth, config=config)]
- created integration_tests/configured_catalog.json and schemas/calls.json.
- able to spec, discover, and read against the desired “calls” endpoint.
- I understand that the calls.json file should contain
propertieswithin the first layer of the dictionary, but the read function only works when I provide thepropertieskey in the third layer of the dictionary.
- I understand that the calls.json file should contain
{
"streams": [
{
"stream": {
"name": "calls",
"json_schema" : {
"$schema": "https://apidocs.callrail.com/calls",
"type": "object",
"properties": {
- Whereas throughout the documentation, I see all the other schema files removing the first 3 keys found resulting in:
{
"$schema": "https://apidocs.callrail.com/calls",
"type": "object",
"properties": {
When I attempt to sync the data, I can see the data coming through with 21 records. I can see the raw source table created in my destination database as well.
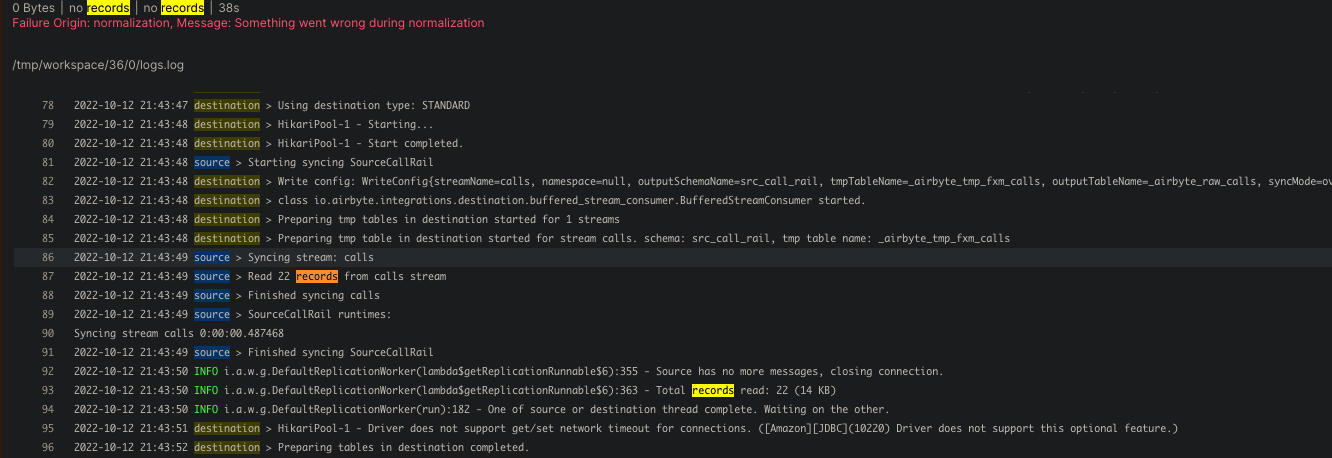
The error that I’m running into leads me to believe that there is something wrong with my json schema. I’ve attached the error log below.
KeyError: "'json_schema'.'properties' are not defined for stream calls"
call_rail_error_logs.txt (133.0 KB)
Any advice would be greatly appreciated!